『エキスパートPythonプログラミング 改訂3版』の紹介¶
エキスパートPythonプログラミング 改訂3版 (原題 Expert Python Programming - Third Edition) が2021/7/30にアスキードワンゴさんより発売されました!(追記)紙版の他、PDF版、EPUB版、そしてKindle等の各社電子書籍版があります。
清水川もこの 「エキPy 3版」 の翻訳に、 1版 、 2版 に引き続き参加しました。

エキスパートPythonプログラミング 改訂3版 / Third Edition¶
タイトル |
|
|---|---|
原題 |
|
著者 |
Michał Jaworski、Tarek Ziadé |
翻訳 |
稲田直哉、芝田将、渋川よしき、清水川貴之、森本哲也 |
出版社 |
KADOKAWA(アスキードワンゴ) |
Price |
3,800円+税 |
ISBN-13 |
978-404-8930840 |
購入 |
エキPyは、どんな本?¶
『エキスパートPythonプログラミング』は、「Pythonを知っている」状態から 「Pythonをマスターしている」状態に成長するための本 であり、また、他の言語をある程度マスターしている人がPythonの世界でどのように活動していけばいいのかを知るのに最も適した本です。Pythonの入門本ではなく、既にある程度Pythonのプログラムを書ける人がこれから活躍していく上で必要な知識を網羅的に習得するための本です。
第1版が発売された2010年当時は、Pythonの本は入門本がいくつかありましたが、Python開発における作法や開発環境について触れられた本は全くありませんでした。そんな中、『エキスパートPythonプログラミング』(第1版)は中級者~上級者に向けて非常に有益な情報:「コンテキストマネージャー」「メタクラス」「名前付け」「パッケージング」「自動ビルド(CI)」「コード管理」「テスト駆動開発」「ドキュメンテーション」「プロファイリングと最適化」「デザインパターン」といった知識を具体的なコードを交えて紹介してくれました。
私が本書の原著に出会ったのは2009年に開催した勉強会( Zope/Plone開発勉強会 )で、共同主催者の @terapyon からの紹介でした。紹介してもらったその場でざっと読み、 内容の濃さに驚きその場でPDF版を購入して読み漁った ことを覚えています。また、1ヶ月後のPySpa合宿に本を持って行って何人かで回し読みし、 @voluntas や @yoshiori の「良い本だね」というコメントをきっかけに、目次を一気に翻訳してblogで公開したりもしました( Expert Python Programming の目次の和訳 )。
今回の "改訂3版" でも、その内容の濃さは健在です 。本書のカバーにあるように "Pythonのベストプラクティスと最新コンセプトを伝授" する、読み応えのある実践的なネタが満載です。EOLを迎えたPython2やPython3.4の話は削除され、イベント駆動プログラミングと型ヒントの話題が追加されました。開発環境まわりの話題としてはDockerとPythonの話題が追加されています。ページ数は改訂2版から100ページ増え、情報の密度はさらにアップしています。このページ末尾に 目次(完全版) を掲載しましたので、どんな内容なのか、ぜひ確認してみてください。
改訂2版からの変更点¶
既に2版を持っている、読んだことがある人は(ありがとうございます!)差分が気になっていると思います。扱っている分野は2版からそれほど変わっていませんが、多くの箇所が「情報最新化」によって 2020年末頃の状況に合わせて更新 されています。このため、「Pythonで開発を行う際の環境周りの最新情報を知りたい」「2版は3年前の本なので人に勧めづらくなった」という方には改訂3版がオススメです。
おおまかに以下に変更点をまとめました。
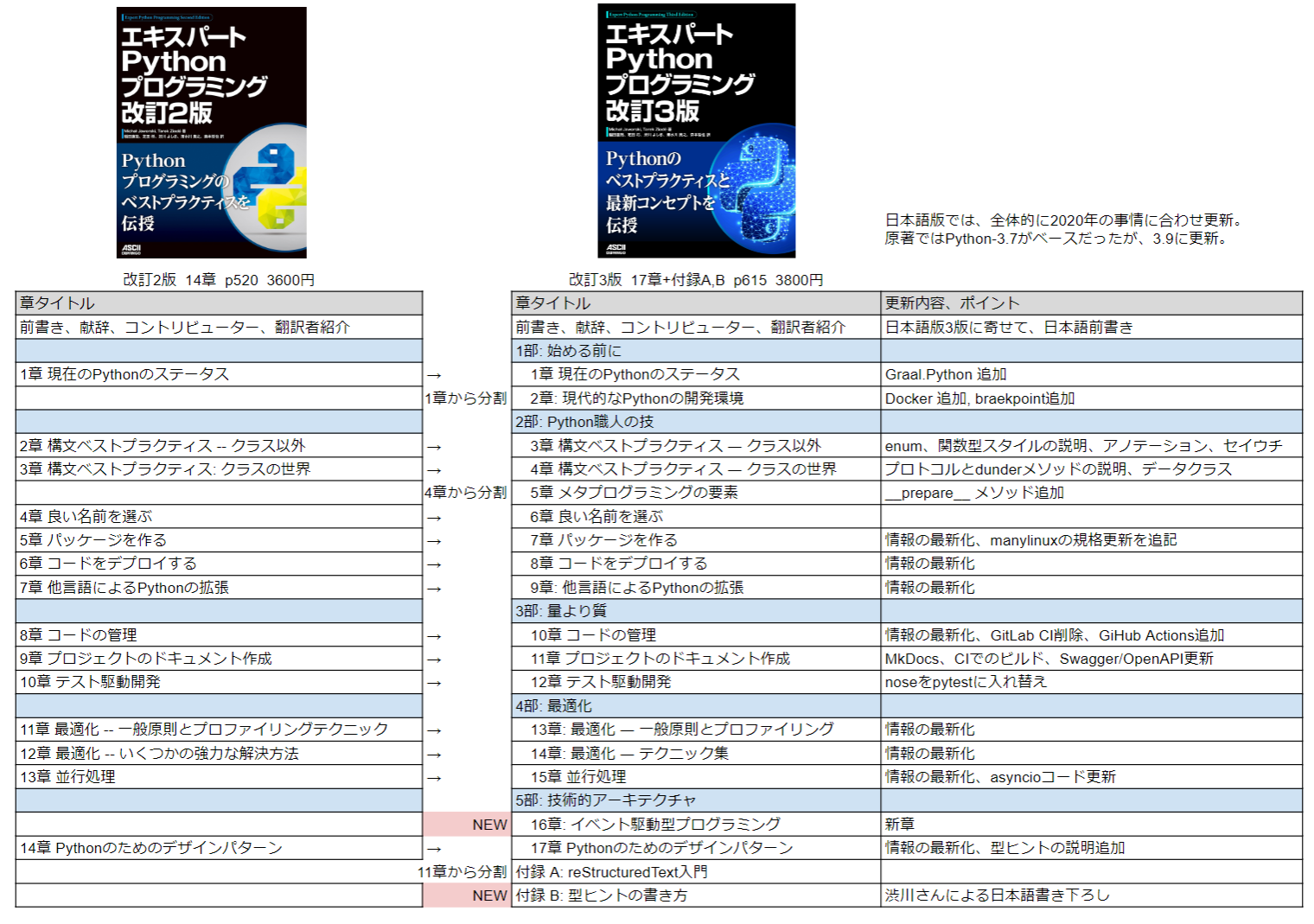
翻訳版のスペック
Pythonバージョン: 3.6 -> 3.9(原著は 3.5 -> 3.7)
ページ数: 520 -> 615
章: 14章 -> 17章+付録A,B
新章: 16章 イベント駆動プログラミング
お値段: 3600円 -> 3800円(200円アップ)
重さ: 933g -> 1kg越え
日本語版での変更点¶
日本語版では、原著3版発売時点(2019年4月)の古くなった情報を更新し、最新情報をノート欄や脚注としてふんだんに追加、一部の文面はがっつり置き換えています。以下、前書きより抜粋します。
1章: CPython以外の処理系としてGraal.Pythonを追加
2章: 3.7で追加されたbreakpoint()関数を追加
2章: DockerでAlpine利用時の注意点を追加、マルチステージビルドを使ったイメージサイズ削減方法を追加
3章: 原著初版で紹介され、2,3版で削除されたジェネレーター式を追加
3章:
itertoolsを追加3章: Python 3.8で追加されたセイウチ演算子(walrus operator)を追加
3章: 型アノテーションの将来期待される用途に関する記述を削除、関連PEPを追加
4章: Python 3.6で追加された
__set_name__メソッドを追加4章: 辞書オブジェクトを集合オブジェクトの代わりに使うテクニックを削除
4章: 旧スタイルクラスに関する説明は、Python 2がEOLを迎えたため削除
5章: Python 2でメタクラスを指定する方法を削除
5章:
__prepare__メソッドでクラスの属性の順番を保持するテクニックを削除7章:
setuptools-svnやsetuptools-hg、setuptools-gitを削除し、setuptools-scmを追加10章: GitLab CI を削除し、GitHub Actionsを追加
11章: API Blueprintを削除
12章:
noseを削除し、pytestの説明を加筆13章: Python 3.3以前にあった循環参照時の
__del__()のメモリリーク問題に関する記述を削除15章: Python 3.4におけるasyncioモジュールの使い方に関する節を削除
17章: 型ヒントに関する記述を更新し、型チェッカー mypy の紹介を追加
付録B: 型ヒントの紹介を日本語版で書き下ろし
目次(完全版)¶
改訂3版の目次です。
1部: 始める前に
1章 現在のPythonのステータス
1.1. 事前準備
1.2. 今どこにいて、どこに向かおうとしているのか?
1.3. Pythonはなぜ/どのように変化するのか?
1.4. PEP文書から最新の変更情報を得る
1.5. 本書執筆時点でのPython 3の普及状況
1.6. Python 3とPython 2の主な違い
1.6.1. なぜそれを気にする必要があるのか?
1.6.2. 主な構文上の違いと、よくある落とし穴
1.6.2.1. 構文の変更
1.6.2.2. 標準ライブラリへの変更
1.6.2.3. データ型とコレクションと文字列リテラルの変更
1.6.3. バージョン間の互換性を保つ時によく利用されるツールやテクニック
1.7. CPython以外の世界
1.7.1. なぜCPython以外も考慮すべきなのか
1.7.2. Stackless Python
1.7.3. Jython
1.7.4. IronPython
1.7.5. PyPy
1.7.6. MicroPython
1.7.7. Graal.Python
1.8. 役に立つリソース
1.9. まとめ
2章 現代的なPythonの開発環境
2.1. 事前準備
2.2. pipコマンドを利用したPythonの追加パッケージのインストール
2.3. 実行環境の分離
2.3.1. アプリケーションレベルの分離とシステムレベルの分離
2.4. Pythonのvenv
2.4.1. venvとvirtualenvの違い
2.5. システムレベルでの環境の分離
2.5.1. Vagrantを使った仮想的な開発環境
2.5.2. Dockerを使った仮想環境
2.5.2.1. コンテナ化と仮想化
2.5.2.2. Dockerfile入門
2.5.2.3. コンテナの実行
2.5.2.4. 複雑な環境の設定
2.5.2.5. Pythonのための便利なDockerレシピ
2.5.2.5.1. コンテナサイズの削減
2.5.2.5.2. docker-compose環境内でのサービスの宛先指定
2.5.2.5.3. 複数のdocker-compose環境間の通信
2.6. 人気のある生産性向上ツール
2.6.1. 拡張インタラクティブセッション - IPython, bpython, ptpythonなど
2.6.1.1. PYTHONSTARTUP 環境変数の設定
2.6.1.2. IPython
2.6.1.3. bpython
2.6.1.4. ptpython
2.6.2. スクリプトやプログラムにシェルを組み込む
2.6.3. インタラクティブ・デバッガー
2.7. まとめ
2部: Python職人の技
3章 構文ベストプラクティス: クラス以外
3.1. 事前準備
3.2. Pythonの組み込み型
3.2.1. 文字列とバイト列
3.2.1.1. 実装の詳細
3.2.1.2. 文字列の連結
3.2.1.2.1. 定数畳み込みとピープホール最適化、AST最適化
3.2.1.3. f文字列を使った文字列のフォーマット
3.2.2. コンテナ
3.2.2.1. リストとタプル
3.2.2.1.1. 実装の詳細
3.2.2.1.2. リスト内包表記
3.2.2.1.3. 他のイディオム
3.2.2.2. 辞書
3.2.2.2.1. 実装の詳細
3.2.2.2.2. 辞書の弱点と代替コレクション
3.2.2.3. 集合
3.2.2.3.1. 実装の詳細
3.3. その他のデータ型とコンテナ
3.3.1. "collections"モジュールの特別なデータコンテナ
3.3.2. "enum"モジュールのシンボル列挙型
3.4. 高度な文法
3.4.1. イテレータ
3.4.2. ジェネレータと"yield"文
3.4.3. デコレータ
3.4.3.1. 一般的な文法と、利用可能な実装方法
3.4.3.1.1. 関数として実装
3.4.3.1.2. クラスとして実装
3.4.3.1.3. パラメータを受け取るデコレータ
3.4.3.1.4. メタ情報を保持するデコレータ
3.4.3.2. 活用例と便利なサンプル
3.4.3.2.1. 引数チェック
3.4.3.2.2. キャッシュ
3.4.3.2.3. プロキシ
3.4.3.2.4. コンテキストプロバイダ
3.4.3.2.5. その他の使用例
3.4.4. コンテキストマネージャ - "with"構文
3.4.4.1. 一般的な文法と、利用可能な実装方法
3.4.4.1.1. クラスとしてコンテキストマネージャを実装
3.4.4.1.2. 関数としてコンテキストマネージャを実装 - "contextlib"モジュール
3.5. Pythonの関数型スタイルの機能
3.5.1. 関数型プログラミングとは何か?
3.5.2. ラムダ関数
3.5.3. "map()"、"filter()"、"reduce()"
3.5.4. 部分オブジェクトと"partial()"関数
3.5.5. ジェネレータ式
3.6. 関数と変数のアノテーション
3.6.1. 一般的な使用方法
3.6.2. mypyによる静的型チェック
3.6.3. 型ヒントの現在と未来
3.7. 知っておくべきその他の文法
3.7.1. "for … else"節
3.7.2. キーワードのみの引数
3.7.3. セイウチ(walrus)演算子による代入式
3.8. まとめ
4章 構文ベストプラクティス: クラスの世界
4.1. 事前準備
4.2. Python言語のプロトコル - dunderメソッドと属性
4.3. データクラスを利用したボイラープレートの削除
4.4. 組み込みクラスのサブクラス化
4.5. MROとスーパークラスからメソッドへのアクセス
4.5.1. Pythonのメソッド解決順序(MRO)を理解する
4.5.2. "super"の落とし穴
4.5.2.1. superと従来の明示的な呼び出しを混在させる
4.5.2.2. 親クラスと異なる引数定義の混在
4.5.3. ベストプラクティス
4.6. 高度な属性アクセスのパターン
4.6.1. ディスクリプタ
4.6.1.1. 現実世界のサンプル - 属性の遅延評価
4.6.2. プロパティ
4.6.3. スロット
4.7. まとめ
5章 メタプログラミングの要素
5.1. 事前準備
5.2. メタプログラミングとは何か?
5.2.1. デコレータ - メタプログラミングの手法
5.2.2. クラスデコレータ
5.2.3. __new__() を使ってインスタンス生成処理をオーバーライドする
5.2.4. メタクラス
5.2.4.1. メタクラスの構文
5.2.4.2. メタクラスの用途
5.2.4.3. メタクラスの落とし穴
5.2.5. コード生成
5.2.5.1. exec, eval と compile
5.2.5.2. 抽象構文木 (AST)
5.2.5.2.1. インポートフック
5.2.5.3. コード生成パターンを使うプロジェクト
5.2.5.3.1. Falconのコンパイルされたルーター
5.2.5.3.2. Hy
5.3. まとめ
6章 良い名前を選ぶ
6.1. 事前準備
6.2. PEP 8と命名規則のベストプラクティス
6.2.1. どうして、いつPEP 8に従うのか
6.2.2. PEP 8 のその先へ - チーム固有のスタイルガイドライン
6.3. 命名規則のスタイル
6.3.1. 変数
6.3.1.1. 定数
6.3.1.2. 命名規則と使用例
6.3.1.3. パブリック変数とプライベート変数
6.3.1.4. 関数とメソッド
6.3.1.5. プライベートの論争
6.3.1.6. 特殊メソッド
6.3.1.7. 引数
6.3.1.8. プロパティ
6.3.1.9. クラス
6.3.1.10. モジュールとパッケージ
6.4. 名前付けガイド
6.4.1. ブール値の名前の前にhasかisをつける
6.4.2. コレクションの変数名は複数形にする
6.4.3. 辞書型に明示的な名前をつける
6.4.4. 汎用性の高い名前や冗長な名前を避ける
6.4.5. 既存の名前を避ける
6.5. 引数のベストプラクティス
6.5.1. 反復型設計を行いながら引数を作成する
6.5.2. 引数とテストを信頼する
6.5.3. 魔法の引数である *args と **kwargs は注意して使用する
6.6. クラス名
6.7. モジュール名とパッケージ名
6.8. 役に立つツール
6.8.1. Pylint
6.8.2. pycodestyleとflake8
6.9. まとめ
7章 パッケージを作る
7.1. 事前準備
7.2. パッケージ作成
7.2.1. 混乱するPythonパッケージングツールの状態
7.2.1.1. PyPAによる、現在のPythonのパッケージングの展望
7.2.1.2. 推奨されるツール
7.2.2. プロジェクトの設定
7.2.2.1. setup.py
7.2.2.2. setup.cfg
7.2.2.3. MANIFEST.in
7.2.2.4. 重要なメタデータ
7.2.2.5. Trove classifiersによる分類
7.2.2.6. よくあるパターン
7.2.2.6.1. パッケージからバージョン文字列の自動取得
7.2.2.6.2. READMEファイル
7.2.2.6.3. 依存パッケージの管理
7.2.3. カスタムセットアップコマンド
7.2.4. 開発時にパッケージを利用する
7.2.4.1. setup.py install
7.2.4.2. パッケージのアンインストール
7.2.4.3. setup.py develop or pip -e
7.3. 名前空間パッケージ
7.3.1. なぜこれが便利なのか?
7.3.1.1. PEP 420 - 暗黙の名前空間パッケージ
7.3.1.2. 以前のバージョンのPythonにおける名前空間パッケージ
7.4. パッケージのアップロード
7.4.1. PyPI – Python Package Index
7.4.1.1. PyPIや他のパッケージインデックスへのアップロード
7.4.1.2. .pypirc
7.4.2. ソースパッケージとビルド済みパッケージ
7.4.2.1. sdist
7.4.2.2. bdistとwheel
7.5. スタンドアローン実行形式
7.5.1. スタンドアローンの実行形式が便利な場面
7.5.2. 人気のあるツール
7.5.2.1. PyInstaller
7.5.2.2. cx_Freeze
7.5.2.3. py2exe と py2app
7.5.3. 実行可能形式のパッケージにおけるPythonコードの難読化
7.5.3.1. デコンパイルを難しくする
7.6. まとめ
8章 コードをデプロイする
8.1. 事前準備
8.2. The Twelve-Factor App
8.3. デプロイを自動化するいくつかのアプローチ
8.3.1. Fabricを用いたデプロイの自動化
8.4. 専用のパッケージインデックスやミラーを用意する
8.4.1. PyPIをミラーリングする
8.4.2. Pythonパッケージに追加リソースをバンドルする
8.5. 一般的な慣習とプラクティス
8.5.1. ファイルシステムの階層
8.5.2. 環境の分離
8.5.3. プロセス監視ツールを使う
8.5.4. アプリケーションコードはユーザー空間で実行しよう
8.5.5. リバースHTTPプロキシを使う
8.5.6. プロセスのgracefulリロード
8.6. 動作の追跡とモニタリング
8.6.1. エラーログ収集 - Sentry
8.6.2. モニタリングシステムとアプリケーションメトリクス
8.6.3. アプリケーションログの処理
8.6.3.1. 低水準ログの基本的手法
8.6.4. ログを処理するツール
8.7. まとめ
9章: 他言語によるPythonの拡張
9.1. 事前準備
9.2. 他言語 ≒ C/C++
9.2.1. 拡張モジュールをインポートする
9.3. 拡張を使う理由
9.3.1. コードのクリティカルな部分の性能を向上する
9.3.2. 別の言語で書かれたコードを利用する
9.3.3. サードパーティーの動的ライブラリを利用する
9.3.4. カスタムのデータ構造を作る
9.4. 拡張を書く
9.4.1. ピュアC拡張
9.4.1.1. Python/C API詳解
9.4.1.2. 呼び出し規約と束縛規約
9.4.1.3. 例外処理
9.4.1.4. GILを解除する
9.4.1.5. 参照カウント
9.4.2. Cythonを使って拡張を書く
9.4.2.1. トランスコンパイラとしてのCython
9.4.2.2. 言語としてのCython
9.5. 拡張のデメリット
9.5.1. 増加する複雑さ
9.5.2. デバッグ
9.6. 拡張を使わずに動的ライブラリを利用する
9.6.1. ctypes
9.6.1.1. ライブラリをロードする
9.6.1.2. C言語の関数をctypes経由で呼び出す
9.6.1.3. Pythonの関数をC言語のコールバックに渡す
9.6.2. CFFI
9.7. まとめ
3部: 量より質
10章 コードの管理
10.1. 事前準備
10.2. バージョン管理システムを使う
10.2.1. 中央集中型システム
10.2.2. 分散型システム
10.2.2.1. 分散の戦略
10.2.3. 中央集中か、分散か?
10.2.4. できればGitを使う
10.2.5. GitFlowとGitHub Flow
10.3. 継続的開発プロセスの設定
10.3.1. 継続的インテグレーション
10.3.1.1. コミット単位でテストする
10.3.1.2. CIを使ってテストしてマージする
10.3.1.3. マトリックステスト
10.3.2. 継続的デリバリー
10.3.3. 継続的デプロイメント
10.3.4. 継続的インテグレーションを行うのに人気のあるツール
10.3.4.1. Jenkins
10.3.4.2. Buildbot
10.3.4.3. Travis CI
10.3.4.4. GitHub Actions
10.3.5. 適切なツール選択とよくある落とし穴
10.3.5.1. 問題1 ―― あまりに複雑なビルド戦略
10.3.5.2. 問題2 ―― あまりに長いビルド時間
10.3.5.3. 問題3 ―― ビルド定義を外部に置く
10.3.5.4. 問題4 ―― 分離の欠如
10.4. まとめ
11章 プロジェクトのドキュメント作成
11.1. 事前準備
11.2. 技術文書を書くための7つのルール
11.2.1. 2つのステップで書く
11.2.2. 対象読者を明確にする
11.2.3. シンプルなスタイルを使用する
11.2.4. 情報のスコープを絞る
11.2.5. 実在するようなコードのサンプルを使用する
11.2.6. なるべく少なく、かつ十分なドキュメント
11.2.7. テンプレートの使用
11.3. ドキュメントをコードのように扱う
11.3.1. Pythonのdocstringを使う
11.3.2. 人気のマークアップ言語とドキュメントスタイル
11.4. ドキュメントを自動生成する有名なPythonライブラリ
11.4.1. Sphinx
11.4.1.1. トップページ
11.4.1.2. モジュール一覧に登録する
11.4.1.3. 索引へ登録する
11.4.1.4. 相互参照
11.4.2. MkDocs
11.4.3. ドキュメントをCIでビルドする
11.5. Web APIドキュメント
11.5.1. Swagger/OpenAPIによるAPIドキュメントの自動生成
11.6. 整理されたドキュメントシステムの構築
11.6.1. ドキュメントポートフォリオの構築
11.6.1.1. 設計
11.6.1.2. 使用方法
11.6.1.2.1. レシピ
11.6.1.2.2. チュートリアル
11.6.1.2.3. モジュールヘルパー
11.6.1.3. 運用
11.7. 自分自身のドキュメントポートフォリオを構築する
11.7.1. ドキュメントランドスケープの構築
11.7.1.1. 作成者向けレイアウト
11.7.1.2. 利用者向けレイアウト
11.8. まとめ
12章 テスト駆動開発
12.1. 事前準備
12.2. テストをしていない人へ
12.2.1. テスト駆動開発のシンプルな3つのステップ
12.2.1.1. ソフトウェアのリグレッションの防止
12.2.1.2. コードの品質の向上
12.2.1.3. 最適な開発者向けのドキュメントの提供
12.2.1.4. 信頼性の高いコードを素早く生産
12.2.2. どのような種類のテストがあるのか?
12.2.2.1. ユニットテスト
12.2.2.2. 受け入れテスト
12.2.2.3. 機能テスト
12.2.2.4. 統合テスト
12.2.2.5. 負荷テストとパフォーマンステスト
12.2.2.6. コード品質テスト
12.2.3. Pythonの標準テストツール
12.2.3.1. unittest
12.2.3.2. doctest
12.3. テストをしている人へ
12.3.1. ユニットテストの落とし穴
12.3.2. 代替のユニットテストフレームワーク
12.3.2.1. py.test
12.3.2.1.1. テストランナー
12.3.2.1.2. テストフィクスチャの作成
12.3.2.1.3. テスト関数とテストクラスの無効化
12.3.2.1.4. 分散テストの自動化
12.3.2.1.5. まとめ
12.3.3. テストカバレッジ
12.3.4. スタブとモック
12.3.4.1. スタブの構築
12.3.4.2. モックの使用
12.3.5. テスト環境と依存関係の互換性
12.3.5.1. 依存性のマトリックステスト
12.3.6. ドキュメント駆動開発
12.3.6.1. ストーリーの作成
12.4. まとめ
4部: 最適化
13章: 最適化 ―― 一般原則とプロファイリング
13.1. 事前準備
13.2. 3つのルール
13.2.1. まず、動かす
13.2.2. ユーザー視点で考える
13.2.3. 可読性とメンテナンス性を保つ
13.3. 最適化戦略
13.3.1. 外部の原因を探す
13.3.2. ハードウェアを拡張する
13.3.3. スピードテストを書く
13.4. ボトルネックを見つける
13.4.1. CPU使用量のプロファイル
13.4.1.1. マクロプロファイリング
13.4.1.2. マイクロプロファイリング
13.4.2. メモリー使用量のプロファイル
13.4.2.1. Pythonはメモリーをどのように扱うか
13.4.2.2. メモリーのプロファイル
13.4.2.2.1. objgraph
13.4.2.3. Cコードのメモリーリーク
13.4.3. ネットワーク使用量のプロファイル
13.4.3.1. 分散トレーシング
13.5. まとめ
14章: 最適化 ―― テクニック集
14.1. 事前準備
14.2. 複雑度の定義
14.2.1. 循環的複雑度
14.2.2. ビッグオー記法
14.3. 正しいデータ構造を選び計算量を減らす
14.3.1. リストからの探索
14.3.1.1. setを使う
14.4. collectionsモジュールを使う
14.4.1. deque
14.4.2. namedtuple
14.5. トレードオフを利用する
14.5.1. ヒューリスティックアルゴリズムや近似アルゴリズムを使う
14.5.2. タスクキューを使って遅延処理を行う
14.5.3. 確率的データ構造を利用する
14.6. キャッシュ
14.6.1. 決定的キャッシュ
14.6.2. 非決定的キャッシュ
14.6.3. キャッシュサーバー
14.6.3.1. Memcached
14.7. まとめ
15章 並行処理
15.1. 事前準備
15.2. なぜ並行処理が必要なのか?
15.3. マルチスレッド
15.3.1. マルチスレッドとは?
15.3.2. Pythonはどのようにスレッドを扱うのか?
15.3.3. いつスレッドを使うべきか?
15.3.3.1. 応答性の良いインターフェイスを作る
15.3.3.2. 仕事を委譲する
15.3.3.3. マルチユーザーアプリケーション
15.3.3.4. スレッドを使用したアプリケーション例
15.3.3.4.1. アイテムごとに1スレッド使う
15.3.3.4.2. スレッドプールを使う
15.3.3.4.3. 2つのキューで双方向に通信する
15.3.3.4.4. エラーの扱いと使用制限
15.4. マルチプロセス
15.4.1. 組み込みの multiprocessing モジュール
15.4.1.1. プロセスプールを使う
15.4.1.2. multiprocessing.dummy をマルチスレッドとして使う
15.5. 非同期プログラミング
15.5.1. 協調的マルチタスクと非同期I/O
15.5.2. Pythonにおける async と await
15.5.3. 非同期プログラミングの実践例
15.5.4. Future を利用して同期コードを結合する
15.5.4.1. ExecutorとFuture
15.5.4.2. イベントループ内でExecutorを使う
15.6. まとめ
5部: 技術的アーキテクチャ
16章: イベント駆動型プログラミング
16.1. 事前準備
16.2. イベント駆動型プログラミングとは何か
16.2.1. イベント駆動 != 非同期
16.2.2. GUIにおけるイベント駆動プログラミング
16.2.3. イベント駆動通信
16.3. イベント駆動プログラミングのスタイル
16.3.1. Callback-basedスタイル
16.3.2. Subject-based スタイル
16.3.3. Topic-based スタイル
16.4. イベント駆動アーキテクチャ
16.4.1. イベントとメッセージキュー
16.5. まとめ
17章 Pythonのためのデザインパターン
17.1. 事前準備
17.2. 生成に関するパターン
17.2.1. Singleton パターン
17.3. 構造に関するパターン
17.3.1. Adapterパターン
17.3.1.1. インターフェイス
17.3.1.2. zope.interfaceを使う
17.3.1.3. 関数アノテーションや抽象基底クラスを使用する
17.3.1.4. collections.abcを使用する
17.3.2. Proxyパターン
17.3.3. Facadeパターン
17.4. 振る舞いに関するパターン
17.4.1. Observerパターン
17.4.2. Visitorパターン
17.4.3. Templateパターン
17.5. まとめ
付録
付録A: reStructuredText入門
reStructuredText
セクション構造
箇条書き
インラインマークアップ
リテラルブロック
リンク
付録B: 型ヒントの書き方
変数の型付け
関数やメソッドの型付け
ユーザー定義クラスの型付け
型よりも厳しく、特定の文字列や数値のリテラルのみを許可する
ジェネリクス
コレクションの種類の使い分け
タプルと他のシーケンスの違い
合併型(Union Type) / オプショナル
あらゆる型を受け付ける"Any"
キャスト
関数のオーバーロード

エキスパートPythonプログラミング 改訂3版¶
